1. O que é machine learning (aprendizado de máquina)?
2. Machine learning, deep learning e inteligência artificial: entenda a relação
3. Como o aprendizado de máquina funciona na prática?
4. Tipos de machine learning
5. Aplicações do aprendizado de máquina
6. Usando o machine learning no mundo corporativo
7. Desafios e considerações éticas no machine learning
8. O lugar do machine learning no futuro da IA
9. Conclusão
A inteligência artificial está cada vez mais presente em nosso cotidiano, e o machine learning, ou aprendizado de máquina, é um de seus principais motores.
A ideia de computadores que aprendem como humanos, antes tema para utopias tecnológicas, hoje é essencial para empresas e organizações processarem e interpretarem grandes volumes de dados, transformando-os em padrões reconhecíveis e ações concretas.
O impacto do aprendizado de máquina, por sinal, não é infundado: de acordo com o instituto de pesquisa Precedence Research, o mercado global de aprendizado de máquina deverá aumentar de US$ 93,54 bilhões em 2025 para cerca de US$ 1.407,65 bilhões até 2034.
Esse valor notável revela muito sobre o potencial dessa tecnologia para a economia global nos próximos anos, ao marcar uma taxa de crescimento anual impossível de ignorar.
Dessa forma, entender os conceitos de machine learning é crucial para quem deseja se destacar na era da inovação. Neste artigo, vamos explorar como ele funciona na prática e como está moldando o cotidiano de pessoas e empresas.
Machine Learning, ou aprendizado de máquina, é um campo da inteligência artificial que capacita computadores a aprender com dados. Em vez de seguir um conjunto rígido de instruções programadas por humanos, esses sistemas são capazes de identificar padrões e fazer previsões ou decisões com base nas informações que recebem.
Em outras palavras, eles "aprendem" com a experiência, tornando-se mais precisos e eficientes à medida que são expostos a mais dados. Por meio do uso de algoritmos, os sistemas analisam as bases fornecidas e criam modelos de acordo com suas descobertas, refinando-os de acordo com seu propósito e com a avaliação de suas entregas.
Ao processar esses dados em grandes volumes, a máquina identifica padrões, reconhece relações e aprende a realizar tarefas ou fazer previsões. Portanto, quanto mais o algoritmo processa, mais preciso e confiável ele se torna, adaptando-se e aprimorando-se continuamente aos propósitos para qual foi projetado.
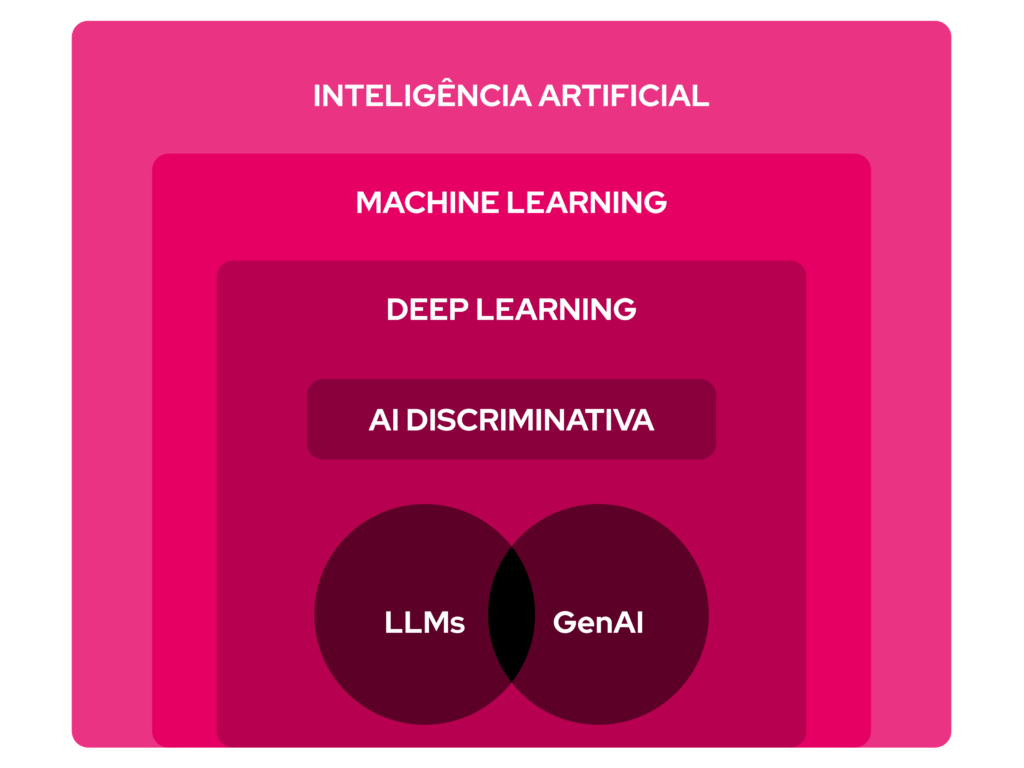
É comum que os termos inteligência artificial, machine learning e deep learning sejam usados de forma intercambiável. Em determinadas situações, até mesmo as redes neurais podem aparecer como um sinônimo.
No entanto, esses conceitos são distintos, embora interligados. Saber a diferença entre eles pode ajudar a compreender melhor o papel de cada um nos resultados que chegam em nossas telas ou que preenchem nosso cotidiano.
A inteligência artificial é o conceito geral e mais amplo dentro desse campo da tecnologia. De modo geral, ele se refere à noção de criar máquinas capazes de imitar o comportamento inteligente humano e resolver tarefas complexas.
Trata-se de um campo vasto que abrange diversas disciplinas para existir, inclusive análise de dados, estatística, engenharia e neurociência. A fim de replicar o funcionamento intrínseco do cérebro humano, inúmeras formas de conhecimento são necessárias.
Por conseguinte, o machine learning é um subcampo da IA, focando especificamente em permitir que sistemas aprendam com dados sem serem explicitamente programados. Em outras palavras, dentro de tudo que compõe a inteligência artificial, o aprendizado de máquina é o recurso responsável por sua capacidade artificial de aprender sozinha.
Dentro do machine learning, encontramos o deep learning (aprendizado profundo), que, por sua vez, é um subcampo específico baseado em redes neurais artificiais (RNAs).
As redes neurais artificiais são modelos computacionais que se inspiram na estrutura e funcionamento do cérebro humano, com camadas de "neurônios" (nós de processamento) interconectados que transmitem sinais. Cada nó processa entradas e produz uma saída.
Além disso, o deep learning utiliza redes neurais com múltiplas camadas, daí o termo "deep" (profundo). Essa profundidade permite que os algoritmos de aprendizado profundo processem grandes quantidades de dados não estruturados, como imagens e áudios, de forma automática e eficiente.
Ademais, enquanto modelos mais simples de aprendizado de máquina operam com dados rotulados por humanos, o aprendizado profundo tem a capacidade inata de trabalhar com dados brutos, ou seja, não rotulados.
Em muitos aspectos, o deep learning é uma forma de machine learning em escala. Afinal, basta que um modelo de machine learning tenha mais de três camadas ocultas para ser classificado como um modelo de aprendizado profundo.
No entanto, ele exige um poder computacional significativo e um treinamento extenso para alcançar seu potencial máximo, sendo uma opção tecnológica que requer mais investimento que modelos de machine learning de entrada.
Em compensação, o deep learning é particularmente eficaz em tarefas como reconhecimento de imagem e fala, além de processamento de linguagem natural, performando melhor com tarefas mais complexas.
Com base em todas essas definições e distinções, o seguinte esquema pode nos ajudar a enxergar melhor como todos os conceitos se relacionam:
Leia mais: Inteligência Artificial: o que é IA e como funciona?
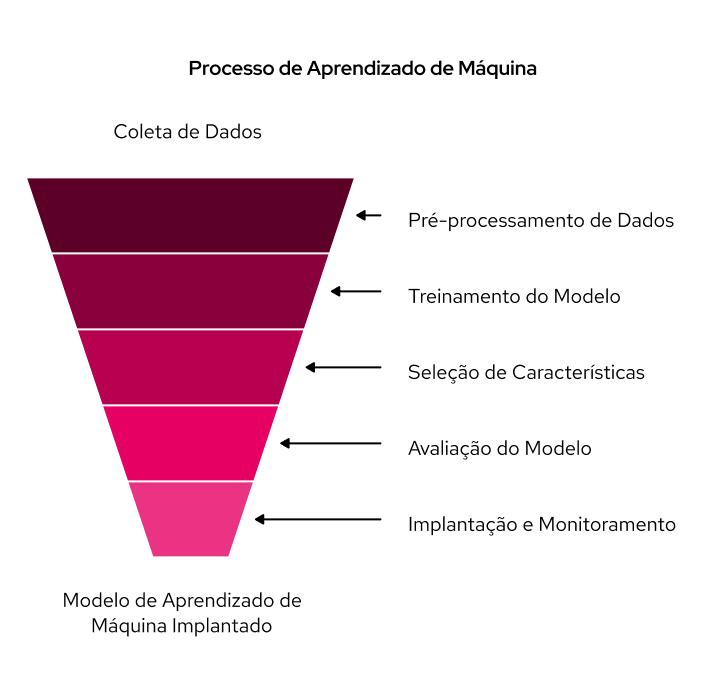
O processo de funcionamento do machine learning é, em síntese, uma jornada que transforma dados brutos em decisões e previsões inteligentes.
Ele geralmente envolve uma série de etapas essenciais que garantem a eficácia e a precisão do modelo.
Tudo começa com a reunião de dados relevantes, que podem vir de diversas fontes, como bancos de dados, sensores, internet ou históricos de transações. É crucial notar que quanto maior e de melhor qualidade for o conjunto de dados, melhor será o aprendizado do modelo.
Os dados coletados raramente estão prontos para uso imediato. Por isso, eles precisam ser limpos, organizados e transformados para garantir sua qualidade e adequação para análise. Isso evita o problema de "garbage in, garbage out" (dados ruins levam a resultados ruins).
Nesta fase, um algoritmo de machine learning é selecionado e alimentado com os dados preparados. O objetivo é otimizar os parâmetros do modelo para que seu comportamento reflita os padrões presentes nos dados de treinamento. O algoritmo atualiza continuamente os valores dos parâmetros à medida que o aprendizado progride, em um processo iterativo de "avaliação e otimização".
Os dados de entrada podem conter muitas variáveis. Frequentemente, o modelo de ML precisa identificar as características mais importantes. A engenharia de features envolve a criação de novas características a partir das existentes para aprimorar a capacidade de aprendizado do modelo.
Após o treinamento, o modelo é avaliado utilizando um conjunto de dados diferente dos usados no treinamento. Isso permite verificar a precisão do modelo e assegurar que ele funciona bem com novos dados, em vez de apenas memorizar os exemplos de treinamento.
Se o modelo for bem-sucedido na avaliação, ele pode ser implantado em aplicações do mundo real. Todavia, para garantir seu desempenho e identificar a necessidade de novos treinamentos ou ajustes, o modelo implantado deve ser monitorado continuamente.
Com todas essas etapas em mente, chegamos à seguinte estrutura para sintetizar o processo de aprendizado de máquina:
Conforme mencionado, o modelo é o produto final, originado a partir de um algoritmo que passou por um processo de treinamento adequado. No final, ele se torna apto a fazer previsões, identificar padrões e executar tarefas de diferentes complexidades.
Nos modelos mais sofisticados e robustos, estruturados com deep learning, bases de dados colossais e incontáveis treinamentos, muita coisa é possível. Exemplos reais e práticos das capacidades de sistemas baseados em bons modelos de machine learning podem ser encontrados em softwares muito familiares para nós, como ChatGPT, Grok e Gemini.
Leia também: GPT: O que significa a sigla do ChatGPT da OpenAI?
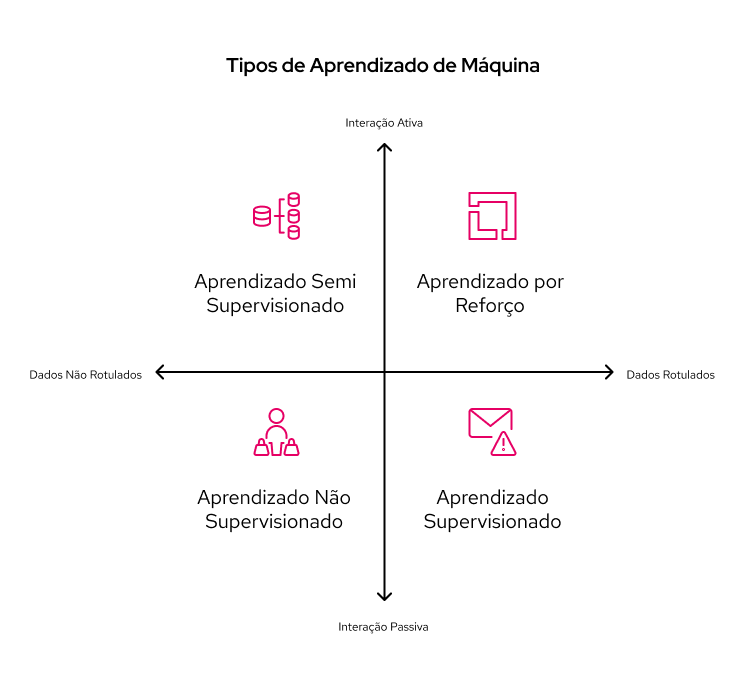
Na prática, o machine learning é categorizado em quatro tipos principais de aprendizado. Cada um desses tipos possui suas próprias vantagens e desvantagens; a escolha do mais adequado depende do problema a ser resolvido, dos dados disponíveis, do objetivo final e claro, do tempo e recursos disponíveis para serem investidos em seu desenvolvimento.
Este é o tipo mais comum de aprendizado de máquina. Nele, os algoritmos são treinados utilizando um conjunto de dados "rotulados". Isso significa que cada exemplo de treinamento já vem acompanhado da "resposta correta" ou do rótulo desejado. Sendo assim, a intervenção humana, ao menos no primeiro momento, é significativamente maior.
O objetivo do algoritmo é aprender a mapear as entradas para as saídas corretas, a fim de fazer previsões precisas para novos dados. Por exemplo: para que um modelo de aprendizado supervisionado diferencie gatos e cachorros em novas entradas, ele precisa ser alimentado com muitas fotos de gatos e cachorros rotuladas adequadamente, para que estabeleça padrões e aprenda a diferenciá-los com base neles.
Modelos de aprendizado supervisionado podem ser utilizados para classificar e-mails como spam, reconhecer rostos em fotos ou prever preços de imóveis. Algoritmos comuns para o desenho desses modelos incluem regressão linear, regressão logística, máquinas de vetor de suporte (SVM) e redes neurais.
Em contraste, neste tipo de aprendizado de máquina, os algoritmos são treinados em um conjunto de dados "não rotulados". Não há respostas corretas fornecidas, e o objetivo é que o algoritmo descubra padrões ocultos, estruturas ou relacionamentos nos dados, sem a necessidade de rótulos humanos.
Geralmente funciona bem para agrupar dados semelhantes, como segmentar clientes pelo seu comportamento de compra, ou para reduzir a dimensionalidade dos dados. Exemplos de algoritmos empregados nesses modelos incluem análise de cluster (clustering) e autoencoders.
Esta abordagem combina características do aprendizado supervisionado e não supervisionado. Sendo assim, é particularmente útil quando se dispõe de um grande conjunto de dados, mas apenas uma pequena parte dele é rotulada, tornando a rotulagem manual cara ou complexa. O algoritmo utiliza as informações dos dados rotulados para guiar o aprendizado nos dados não rotulados, melhorando o desempenho geral do modelo.
Diferentemente dos outros tipos, o aprendizado por reforço treina algoritmos por meio da interação contínua com um ambiente. O algoritmo realiza ações em um contexto e recebe feedback na forma de recompensas ou penalidades. O objetivo é que ele aprenda a sequência de ações que maximiza a recompensa total ao longo do tempo.
Por fim, profissionais aplicam esse recurso com frequência em jogos, robótica, sistemas de recomendação e no treinamento de veículos autônomos, onde cada decisão influencia os resultados futuros. Um sistema projetado para jogar damas, por exemplo, emprega aprendizado por reforço, pois ele precisa aprender a perder algumas peças para vencer uma partida.
Para compreender os tipos de machine learning de forma mais objetiva, podemos pensar em uma organização em quadrantes com base na rotulagem dos dados e no nível de atividade da interação exercida. Aplicando-os em um gráfico, chegamos ao esboço abaixo:
O machine learning já transcendeu os limites do ambiente acadêmico e impulsionou inovações que impactam diversas indústrias e aspectos de nossas vidas. Sua capacidade de processar vastas quantidades de dados em tempo real o posiciona como uma ferramenta extremamente poderosa.
Em vista disso, ele está presente em inúmeras atividades de nossa rotina, otimizando processos e oferecendo soluções inteligentes. Dentre as suas inúmeras aplicações, podemos destacar:
Ademais, além dessas aplicações gerais, o machine learning é a base para soluções mais específicas e personalizadas. A AI Factory do Distrito, por exemplo, utiliza ML e outras tecnologias de IA para desenvolver soluções customizadas para grandes corporações.
O investimento em machine learning não é apenas uma questão de acompanhar as tendências tecnológicas, mas sim uma estratégia fundamental para impulsionar a inovação e o crescimento dos negócios.
As empresas que adotam o aprendizado de máquina podem colher uma série de benefícios tangíveis que as posicionam na vanguarda do mercado.
Apesar do imenso potencial do aprendizado de máquina, sua implementação e uso também apresentam desafios significativos e levantam importantes considerações éticas. A fim de garantir um desenvolvimento e aplicação responsáveis, é fundamental estar ciente desses pontos:
Modelos complexos de machine learning podem funcionar como "caixas pretas". Isso significa que compreender por que o modelo tomou uma decisão ou alcançou determinado resultado é uma tarefa difícil.
Tal fato é problemático em aplicações críticas, como diagnósticos médicos ou sistemas de justiça, onde a rastreabilidade e a confiança são essenciais.
Por isso, é importante não tratar esses modelos como oráculos, mas sim buscar entender as regras aprendidas e validá-las, visto que os modelos podem se enganar ou falhar em tarefas simples para humanos. Afinal, no processo de aprendizagem, o feedback é um componente inseparável.
Modelos de ML aprendem com os dados que recebem. Se os dados de treinamento refletirem vieses humanos ou desigualdades existentes na sociedade, o modelo aprenderá e perpetuará esses vieses.
Como resultado, isso pode levar a resultados discriminatórios em diversas aplicações, como contratação de funcionários, concessão de crédito ou até mesmo em sistemas de reconhecimento facial.
Dessa forma, é fundamental revisar cuidadosamente os dados de treinamento e promover abordagens éticas para mitigar esses riscos.
Os modelos de machine learning exigem grandes e precisos conjuntos de dados para treinamento. A aquisição de dados suficientes e de alta qualidade pode ser um verdadeiro dreno de recursos, enquanto dados inadequados, imprecisos ou com vieses podem levar a algoritmos errados ou enganosos.
A privacidade dos dados e a segurança são preocupações crescentes no campo do ML. Os dados utilizados podem conter informações confidenciais ou proprietárias. Além disso, os dados podem ser alvo de ataques cibernéticos com o objetivo de contaminar o modelo e criar informações incorretas nos resultados.
Sendo assim, políticas rigorosas e investimentos em segurança são essenciais para proteger as informações pessoais e sensíveis.
Quando um sistema autônomo causa um erro, quem é o responsável? A falta de um mecanismo claro para aplicar regras e a responsabilidade distribuída na construção de sistemas de IA dificultam a garantia de práticas éticas. Embora estruturas éticas estejam sendo desenvolvidas, elas ainda servem principalmente como guias.
Implementar projetos de aprendizado de máquina exige um investimento significativo em infraestrutura, softwares e profissionais qualificados. Consequentemente, o desenvolvimento e a manutenção dos algoritmos são um processo contínuo que demanda cientistas de dados e programadores para entender e utilizar os algoritmos de treinamento e seus resultados.
Para enfrentar esses desafios, é de suma importância que organizações e desenvolvedores considerem as implicações sociais e éticas do ML, buscando transparência, justiça e responsabilidade no uso dessas tecnologias.
O machine learning é, sem dúvida, uma parte vital no caminho para a criação de máquinas que possuam capacidades avançadas de raciocínio, aprendizado e adaptação. A busca final da inteligência artificial é construir sistemas que exibam comportamentos inteligentes em um sentido mais amplo.
Nesse sentido, os avanços contínuos em arquiteturas de deep learning, técnicas de aprendizado não supervisionado e autoaprendizado, bem como a expansão das aplicações para novas áreas como IoT, computação quântica e neurociência, garantem que o campo do ML continue a evoluir rapidamente.
A integração do ML com a IA Generativa (GenAI), por exemplo, está abrindo novas possibilidades para a criação de conteúdo e soluções inovadoras.
Em síntese, o futuro do machine learning dentro da IA é promissor e desafiador ao mesmo tempo. À medida que a tecnologia se torna mais poderosa e difundida, a ênfase no uso responsável e na mitigação de riscos cresce.
O desenvolvimento e a adoção de padrões e diretrizes éticas serão cruciais para maximizar os benefícios do machine learning e minimizar seus riscos para a sociedade.
Por isso, empresas que desejam se manter relevantes precisarão não apenas entender o potencial do ML, mas também como aplicá-lo de forma ética e estratégica para resolver problemas de negócio reais.
Não se trata apenas de usar a tecnologia pela tecnologia, mas sim de focar nos problemas que ela pode resolver e no valor que pode gerar.
Compreender o machine learning é um passo fundamental para navegar com sucesso na era da inteligência artificial. É uma área em constante evolução, com potencial para gerar resultados significativos para negócios de todos os portes.
Replicar a inteligência humana evidentemente não é uma tarefa fácil, mas o aprendizado de máquina é o primeiro passo nessa longa jornada. Quem entender isso primeiro, seja pessoa ou empresa, tem uma grande oportunidade nas mãos para vivenciar o futuro revolucionário da tecnologia na linha de frente.
Se você está mergulhado em um ambiente corporativo e deseja transformá-lo por completo com aprendizado de máquina e inteligência artificial, o curso Mastering AI for Business do Distrito é o programa executivo ideal.
Líderes e equipes que querem ir além da teoria encontram neste programa uma forma prática, estratégica e personalizada de implementar IA e assumir a dianteira do mercado com inovação e proatividade.
Conheça o programa e leve sua empresa para o próximo nível com IA aplicada à estratégia de negócio!